
« The Termlist Table | Home | Low-Hanging Key Size Reduction »
Xapian's position table holds positional information for terms. That is, given a term and a document id, it can tell you at what positions the given term appears in the given document (assuming you decide to record this information at indexing time). This is used to implement phrase searching and similar features.
The format chert uses is unchanged from that used by flint, so see the description of the format of flint's position table on the Xapian wiki for details.
For most databases (including gmane's) this is the largest table by quite a margin. It's often as large as the others put together.
Table size: 9,823,202,853 entries in 27,068,479 8KB blocks (206.5GB).
(Yes, nearly 10 billion entries!)
| Level | Number of blocks | Comment |
|---|---|---|
| 3 | 1 | The root block |
| 2 | 142 | |
| 1 | 61,458 | |
| 0 | 27,006,878 | Leaf blocks, which hold the tag data |
Key size range: 3 to 70 bytes (mean 10.35).
Frequency range: 3 to 1,610,372,078 occurrences of a particular key size.
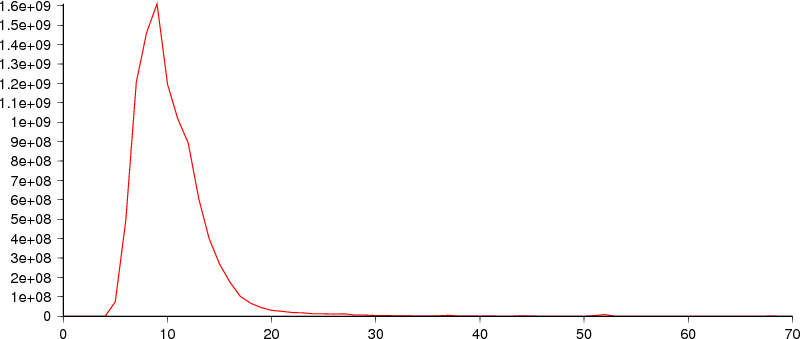
The key is built from the document id (stored as the keys for the record and termlist tables - a length byte, then the big-endian value with leading zero bytes dropped), with the term name appended. With 71 million documents, most entries will have 1 length byte and 4 docid bytes - the average is actually about 4.76 bytes. The average English word is apparently 5.10 characters would give an average term length of 9.86 bytes - pretty close to the observed mean of 10.35.
If we used a numeric termid for the key, then this database has 142,942,820 distinct terms which would encode as an average of 4.88 bytes using the same length-byte-prefixed sortable encoding for an average of 9.64, which is a reduction of 0.71 bytes per entry, or nearly 6.5GB.
If we also specialise the key function per table, we could knock another whole byte off that and save a total of 15.6GB.
And we don't need a whole byte to store the length of the docid - we can use 3 bits and still support 264 documents, while using the other 5 bits to store the highest bits of the docid, which should typically save another 5/8 of a byte per item - that's a total of 21.4GB.
Tag size range: 1 to 15,950 bytes (mean 3.11).
Frequency range: 1 to 3,585,463,883 occurrences of a particular tag size.
Total size of all tags is 29,151.6MB (or 28.5GB).
At first glance, the plotted red line may not be obvious - the graph starts at a maximum very close to the X-axis, decaying quickly to small values very close to the Y-axis.
This plot has log(1 + frequency) on the Y axis and shows the distribution more clearly:
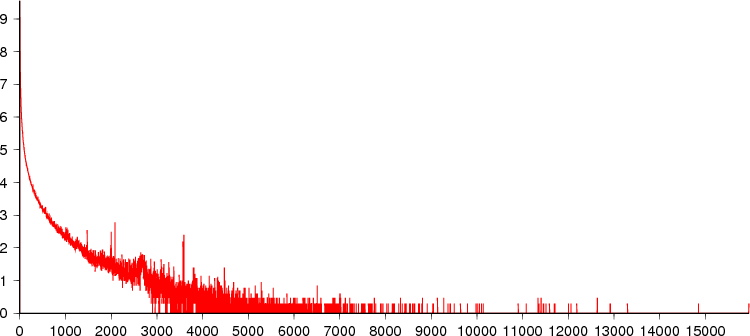
The surprising thing here is that most entries are so short - I guess this shows how effective the interpolative coding technique is. The average key is more than 3.3 times the size of the average tag.
It might be worth considering storing the positional data for each term as a chunked stream, as we do for postings - we could store a few hundred short entries in a chunk requiring only a single (albeit slightly more complex) key.
| Item | Total size (bytes) | Per entry (bytes) | Per leaf block (bytes) |
|---|---|---|---|
| Per entry overhead | 88,408,825,677 | 9.0000 | 3,273.5670 |
| 61,601 branch blocks | 504,635,392 | 0.0514 | 18.6854 |
| Unused space in leaf blocks | 302,262,121 | 0.0308 | 11.1920 |
| Leaf block headers | 297,075,658 | 0.0302 | 11.0000 |
| Overhead in leaf blocks from split tags | 12,870,336 | 0.0013 | 0.4766 |
There are 721,568 continuation items for the 9,823,202,853 entries, which isn't all that many - avoiding splitting tags would only save 12.2MB.
Again, the per entry overhead is the most substantial of these (and the others are much less than a byte per entry in total).
It seems pretty clear that this table is currently rather inefficient in terms of disk space. The total size of the tags is 28.5GB, but the table is 206.5GB. We do need some overhead for the keys and other table structure which allow us to efficiently find an item, and to add, delete or replace items, but it shouldn't need to be so high.
This table is also almost 50% larger than all the others put together, and has more than 13 times as many entries as all the others put together, so per-block and per-item savings are particularly worthwhile here. Each byte off the per-entry overhead would save 9.1GB. Decreasing the average size of the key and specialising the key comparison function would also make a big difference.
Prefix-compressing keys would help, but covers some of the same ground that decreasing the key size would.
Storing the positional data as chunked streams is worth considering too.
Posted in xapian by Olly Betts on 2009-12-15 14:41 | Permalink
« The Termlist Table | Home | Low-Hanging Key Size Reduction »