
« The Postlist Table | Home | The Position Table »
The termlist table stores the list of terms for each document. This is used to allow postlist entries to be removed when documents are deleted or replaced, to report which query terms match a given document, and to implement query expansion.
If your documents have more distinct terms then the termlist tags will tend to be larger, though we store the terms sorted with common prefixes eliminated which will tend to save more for longer lists of terms.
Table size: 70,978,511 entries in 8,632,963 8KB blocks (67,445.0MB).
| Level | Number of blocks | Comment |
|---|---|---|
| 3 | 1 | The root block |
| 2 | 33 | |
| 1 | 16,603 | |
| 0 | 8,616,326 | Leaf blocks, which hold the tag data |
Key size range: 2 to 5 bytes (mean 4.76).
Frequency range: 255 to 54,201,296 occurrences of a particular key size.
The key format is the same as that of the record table, and again we could shorten all keys by a byte if the sort routine could be specialised for each table.
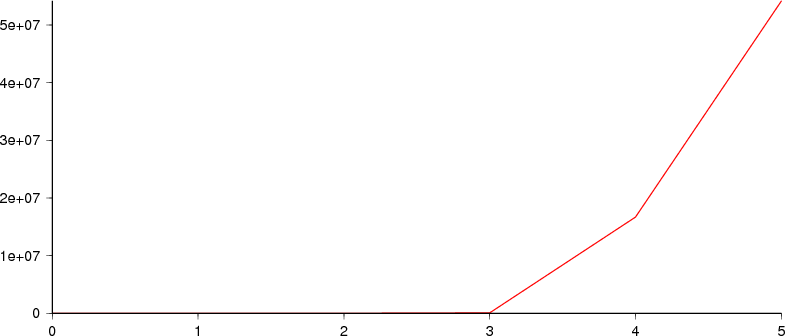
Tag size range: 24 to 621,628 bytes (mean 972.85).
Frequency range: 1 to 80,928 occurrences of a particular tag size.
Total size of all tags is 65,852.9MB.
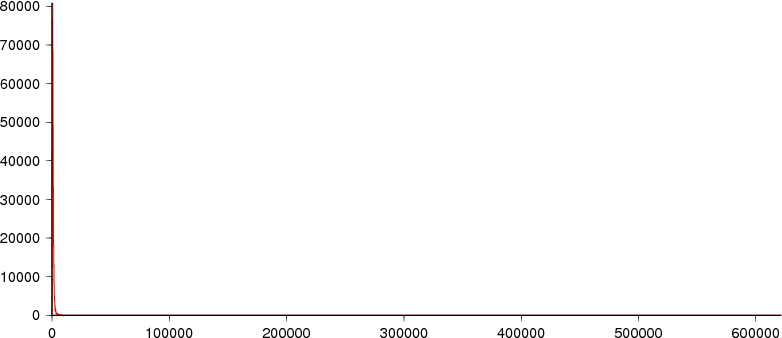
While there are some really long tags, most are fairly modest in size (although note the X-axis scale - the first tick is 100,000 bytes).
This plot has log(1 + frequency) on the Y axis and shows the distribution more clearly:
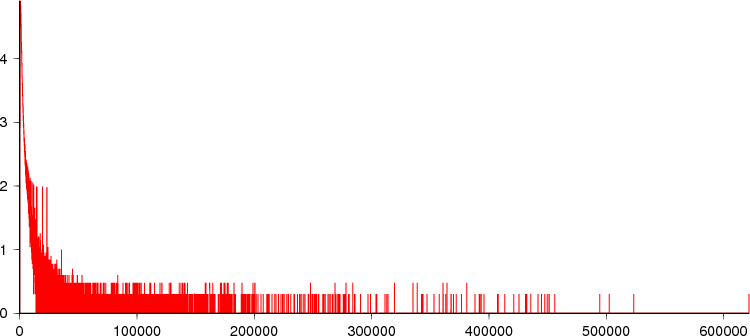
There are 32,634,436 continuation items for the 70,978,511 entries. Most tags aren't getting split, but many of those that are require a lot of continuation items.
| Item | Total size (bytes) | Per entry (bytes) | Per leaf block (bytes) |
|---|---|---|---|
| Per entry overhead | 638,806,599 | 9.0000 | 74.1391 |
| Overhead in leaf blocks from split tags | 448,812,840 | 6.3232 | 52.0887 |
| 16,637 branch blocks | 136,290,304 | 1.9202 | 15.8177 |
| Leaf block headers | 94,779,586 | 1.3353 | 11.0000 |
| Unused space in leaf blocks | 12,748,180 | 0.1796 | 1.4795 |
Unlike the previous tables we've looked at, the "per entry overhead" isn't so dominant here. We're losing a lot of space from having to split large tag values into a lot of <2KB pieces, and being able to store large tags unsplit would make a great difference here. Reducing the per entry overhead would be worthwhile too.
Being able to specialise the key comparison function would allow keys to be a byte shorter, though prefix compressed keys would probably be somewhat redundant with that.
Posted in xapian by Olly Betts on 2009-12-14 20:27 | Permalink